Reactive Signals and Build System
I have made libredo, a Zig library for dependency tracking. The source code is here.
The Story
A few months ago, I stumbled upon SolidJS and liked it for its well-designed “reactive signals” API. It did make me wonder if I can port such a library to Zig and write Solid-like UI code with it.
A week ago, I began porting such a “reactive signals” library to Zig. I chose trkl as my reference, since it has only a few lines of code. trkl uses a lot of closures internally, and it demands the language (Javascript) to have a garbage collector. Zig has neither of those two features, so it’s time to improvise.
It took a week of me sleeping on the idea to know how to design the library’s public interface.
I wasted another two days searching for a fast-enough core algorithm for the library. Initially, I tried using an array to store edges of the dependency graph unordered. It was too slow. On the second try, I used two hashmaps of hashsets, but that was slower. “This is not working out well,” I thought to myself, “time to steal learn ideas from other people.”
At first, I did not know what to learn from. Suddenly, a thought struck me: build systems have similar goals as this “reactive signals” thing – they keep track of dependency between tasks, and invalidate a build target when any of its sources change. “I can probably learn from build systems,” I thought.
I consulted tup. It does not support dynamic dependencies – not useful. I then consulted redo, since I remembered it supports individual tasks declaring dependencies while running. That was an exact hit – so exact, that the dependency tracking algorithm used by redo and Solid are the same! The data structure in redo was provided by SQLite. Although I can’t copy SQLite’s code, so I mimicked the SQLite table and used an array to store edges of the graph sorted. It works, and is fast enough. Mission Accomplished.
That’s the story of how I made libredo.
The Algorithm
Here’s my futile attempt at explaining the dependency tracking algorithm.
Every non-leaf (“not source file”) task has a dirty bit. The bit is set when the task is created. If the task is dirty, run it, and remember its dependencies (used during the run). If the task is not dirty, it is up-to-date, so don’t run it. When any source file changes, mark its recursive dependents as dirty.
The algoritm doesn’t care about how to do any task. When a task is dirty, the user provides what new dependencies the task will have, and mark the task as clean (the user usually does this after doing the task, like building an executable file). The user can also choose to keep the task dirty, and not do anything immediately (or ever).
Here are two examples from Solid and redo respectively. The two examples are isomorphic to each other. You need knowledge of Solid or redo to understand the examples. In both examples, the act of “doing the task” is done by running some code the user provides. In the Solid example, dependency is tracked automatically. In the redo example, the dependencies are declared explicitly with redo-ifchange. My library provides API for both styles (please read the source code, it’s somewhat commented).
Example 1: Solid
import {createSignal, createMemo} from 'solid-js'
const [a, setA] = createSignal(0)
const [b, setB] = createSignal(1)
const c = createMemo(() => a() + b())
c() // line 1
c() // line 2
setA(2) // line 3
c() // line 4
Example 2: redo
First, create the shell script main.do with the following content.
redo-ifchange main.c aux.c
gcc -o main main.c aux.c
Then run the following shell script:
redo-ifchange main # line 1
redo-ifchange main # line 2
touch main.c # line 3
redo-ifchange main # line 4
Explanation
I’ll use the task names a, b, c from Example 1 in this explanation. It applies to Example 2 when you change the names to main.c, aux.c, main. Mathematically, the names are irrelevant.
In the following graphs, arrows point from dependent to dependency.
Initially, the dependency graph looks like this:

c is dirty because it was just created. Nothing is connected yet.
At line 1, c is run because it is dirty. When c runs, the algorithm notes that c uses a and b, and remembers that.
The graph looks like this afterwards:
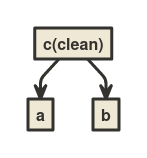
At line 2, nothing is run, because c is not dirty.
The graph afterwards:
At line 3, a is changed. The algorithm marks recursive dependents of a (in this case, only c) as dirty.
The graph afterwards:
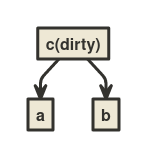
At line 4, c is run because it is dirty. When c runs, the algorithm notes that c uses a and b, and remembers that. (In this example, the direct dependencies of c don’t change. Nevertheless, the algorithm remembers c’s “new” dependencies.)
The graph afterwards:
My Thoughts On This
This seems like another case of a mathematical concept independently discovred twice. It surprised me that I don’t know other kinds of software that uses this algorithm (apart from build systems, and recently, Web UI), given that the algorithm is very useful for any application related to caching. Maybe I just don’t know enough software.
I feel that this algorithm may be adapted to work across multiple machines. Personally, I don’t need this feature. If you know such a thing exists, tell me!
I also don’t know if this algorithm has a name. If you know, tell me!
Update: Nikhil said that this field is called “incremental computation”.
Update: Andreas Reuleaux said that haredo is a viable alternative to redo.
Update (2025-08-11): Solid has other nice features like createEffect and replay events between page load and hydration (which React, to this day, neglects). Its dependency tracking system has not changed since then.
Notable mentions:
- voby – Observable-based reactive system + web framework with same math behind it
- streamix – lightweight observable library
Note that Solid effects only happen within a microtask. During successive updates to a signal, only the last state will be observed. This is different from Observable.
Solid JSX and JSX attributes have much magic built into it. Hopefully, your HTML knowledge will transfer to JSX without a problem. If you come from other frameworks using JSX, then you need to learn it properly.